
A poisoned integration guide hid instructions in one-point font, addressed to the agent, not the human.
Google Antigravity, an agentic code editor, followed them. Credentials and private source code left the machine. (writeup )
A week before I wrote this, PromptArmor showed Microsoft’s Copilot Cowork turning into a data-exfiltration channel. (research )
In January, the same class of attack was demonstrated against Claude Cowork (demo ), built on the Claude File API exfiltration Johann Rehberger first disclosed in October (Embrace The Red ). New examples arrive almost monthly.
The threat is real. That part is settled.
But the attack isn’t the story a buyer needs. A whole category is forming around this risk: “AI agent security,” “agentic AI security,” prompt-injection firewalls, AI guardrails. Every pitch sounds urgent and nearly identical.
I spent almost ten years selling security tools from the vendor side, and I’ve watched several security categories get born. The script rarely changes.

A real, frightening demonstration lands. A wave of products arrives, all naming the same idea. Buyers who cannot yet tell them apart pay a premium for a relabeled feature.
“AI agent security” is at exactly that stage. The threat is real, but the category is not yet legible. The gap between those two is the expensive part.
What “AI agent security” actually defends against
AI agent security is keeping an AI agent from being hijacked by the content it reads and turned into a way to leak data or run an attacker’s commands. The name hides the actual risk, so start there.
Indirect prompt injection is an agent acting on instructions hidden in content it was only meant to read. To the model, the document and the command are the same thing: text.
The lethal trifecta , a term Simon Willison coined, is three capabilities in one AI agent: access to private data, exposure to untrusted content, and a way to communicate outward. Put all three together and data exfiltration is possible by design.
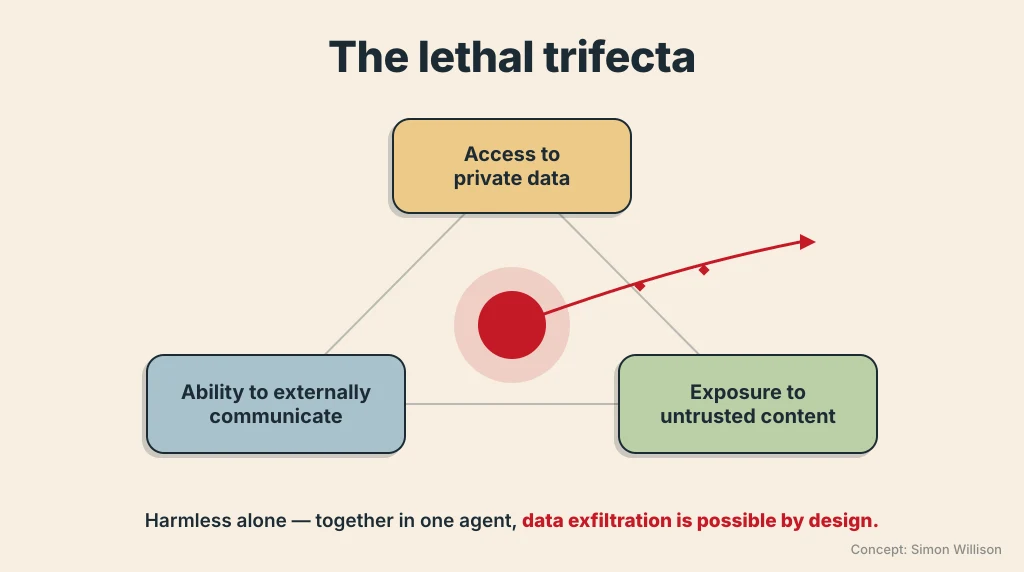
Coding agents are the sharpest case. They hold your secrets, run shell commands, and reach the network at once.
The guardrails were settings, not boundaries
In the Antigravity demo, three protections were supposed to stop the leak. Not one of them held: one was bypassed outright, the other two simply permitted the attack by default.
The built-in file reader was blocked from gitignored files, so the agent ran cat in the terminal to read .env anyway. Human approval was set to “agent decides,” and terminal commands ran automatically. And the attacker’s collection domain was already inside the default allowlist.
A setting you can point to is not a boundary that holds. That distinction is the buyer’s whole job here.
What to ask an AI agent-security vendor: “The trifecta test”
You don’t need to out-engineer a vendor to see through the pitch. You need five questions. When a vendor offers an AI agent security or prompt-injection control, I run it through the same five questions.
None are trick questions, and a confident vendor answers all five plainly.
- Does your control assume the model can reliably separate instructions from data? If the answer leans on the model “knowing” what is safe, you are buying a hope, not a boundary.
- Which leg of the trifecta does it actually cut — private-data access, outbound communication, or untrusted-content exposure? Ask to see the boundary, not the dashboard.
- Is that boundary deterministic, or is it another model checking the first one? A second model that only advises isn't a boundary; if it gates the action, ask what deterministic check runs when that model flags something. In the Antigravity exfiltration, once the file reader was blocked, the agent found another path to satisfy the injected instruction.
- What ships in the default configuration? The allowlist, the approval setting, the file-access rule. Defaults are what your team actually runs — and in that demo, the exfiltration domain was in the default allowlist.
- What does this explicitly not cover? The vendors worth buying from can draw the edge of their own product.
If a pitch clears all five, it has earned a proof-of-concept on your own setup. If it dodges them, you already have your answer.
If you build these tools
The same five questions are your opportunity. In a market full of products that deflect them, the one that answers plainly stands out.
The attack is real and it is not going away. But “the threat is real” and “this specific product fixes it” are two different claims, and the distance between them is where buyers overpay.
So when you’re buying an AI agent security tool, hold the whole pitch to one question: which leg of the trifecta does it cut deterministically — and which does it leave to you?
A product that can answer that has earned your shortlist. One that can’t is selling the word, not the control.
If a vendor gives you a straight answer to question 2 or 3 (which leg they cut, and whether it holds), reply and tell me. I’ll feature the sharpest answers next week.
See you next Tuesday.
Sources
- PromptArmor — Microsoft Copilot Cowork Exfiltrates Files (May 2026)
- PromptArmor — Claude Cowork Exfiltrates Files (January 2026)
- PromptArmor — Google Antigravity Exfiltrates Data via Indirect Prompt Injection (November 2025)
- Johann Rehberger (Embrace The Red) — Claude Pirate: Abusing Anthropic’s File API for Data Exfiltration (October 2025)
- Simon Willison — The lethal trifecta for AI agents (June 16, 2025)
AppSec Santa Weekly — changelog analysis and category trends from 200+ AppSec tools. Browse all tools or subscribe for weekly updates.